Unilib - программа для создания локальных библиотек.
Unilib представляет собой развитый офлайновый каталогизатор локальной библиотеки с автоматизированной пакетной обработкой импортируемых книг. Программа позволяет производить автоматический отбор книг по критериям, заданным пользователем, отсеивать дубликаты и.т.д.
Особенности Unilib-а:
1) Поддержка нескольких библиотек. 2) Импорт/экспорт личных данных. 3) Возможность обмена данными с другими библиотеками Unilib.
А за вот это: Группа: Друзья Просто этот тип группы появился позже и по-умолчанию атрибуты не установились Поправил вроде...Проверяем...
На всяк https://yadi.sk/d/0_R1CIX53HmCsE Хотя, на сколько я помню, у Вас всё уже поправлено (кроме номера версии) и работает. Это я в основном для новичков сделал, что бы все ссылки на отдельные правленые файлы не искали. Но навсяк, можно и переписать. drSerj
Хотя, на сколько я помню, у Вас всё уже поправлено (кроме номера версии) и работает.
Спасибо, понял! Все чего-нибудь да стоит... Просто срабатывает инстинкт на новую версию... а вдруг там что-то такое есть... =============================== Приказ, который может быть понят неправильно, обязательно будет понят неправильно
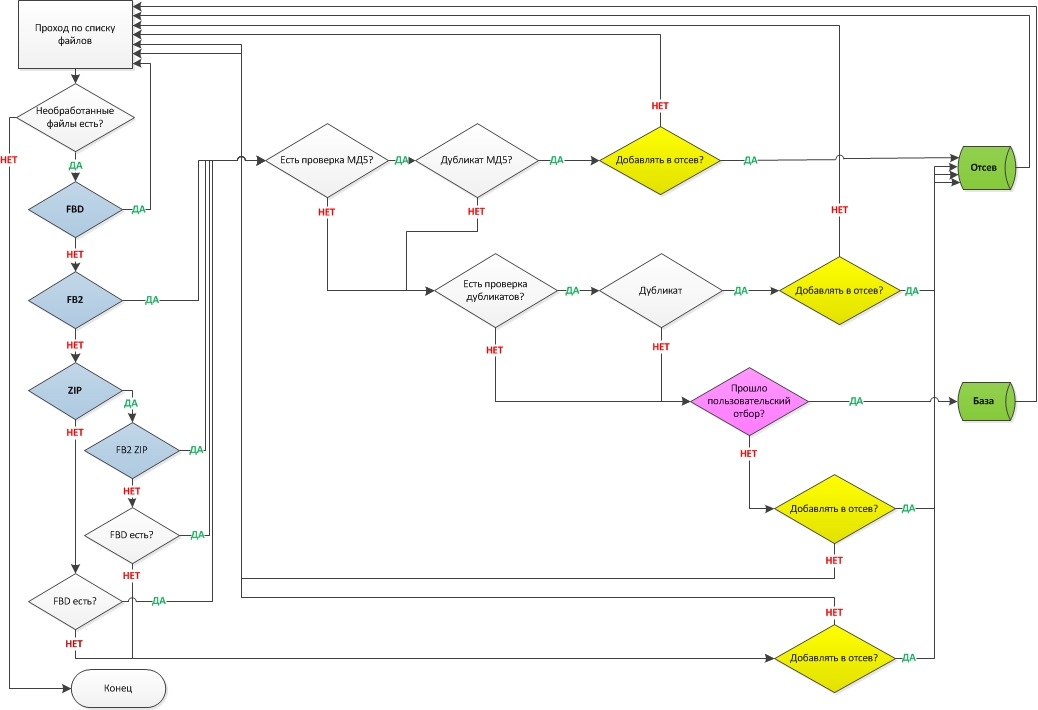
Так, небольшие уточнения по алгоритму импорта. Имеем следующую схему (к элементам не придираться, сам знаю что не всё правильно )
Как видно из схемы, отсевы идут в 4 направлениях (с уточняющими кодами), можно пускать в отсев не всё. Дубликаты двух типов: МД5 и Пользовательский (название, и т.д. кое-кто обещался подкинуть). Пока только архив типа ZIP, может в будущем добавится еще что-нить. Предупреждая возражение некоторых товарищей, а как же FBD без файлов - сразу скажу, тут нет и не будет, это импорт не базы а книг. По этому, если имеется FBD без книги - в игнор.
Да, посты о проблеме с мультилибом между мной и grock-ом я перенес в соответствующий теме топик http://libruslib.ucoz.com/forum/36-121-96 дабы не засорять обсуждение юнилиба. drSerj
Я посмотрел схему. Возник только один вопрос: почему из "Базы" и "Отсева" снова возвращаемся в "Проход по списку файлов"? С Базой еще можно согласиться, а с Отсевом - непонятно. Эти файлы или должны редактироваться или удаляться без следа! Особенно совпавшие по МД5.
Фильтр Пользовательского отбора стоит непосредственно перед добавлением в базу. Предлагаю конкретнее определиться с этим отбором: На самом 1-ом этапе если имена файлов имеют вид: 12345.* пользователь может фильтровать/отбирать файлы только по расширению или языку. Поэтому этот фильтр, на мой взгляд, нужно ставить ДО проверки по МД5, чтобы ускорить процесс.
Что касается отсеивания дубликатов по названию книги, то эту процедуру лучше делать уже непосредственно в базе, задействуя разные варианты поиска/отбора.
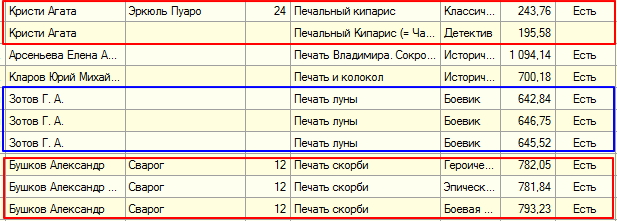
Сегодня, ради эксперимента, загрузил в базу список книг из архива Флибусты. Имена файлов в архиве были как показал выше. В таблице все книги отсортировал по названию и получил:
Этот скрин из моей программы. В ней я могу спокойно удалять все прямо с диска.
Это фрагмент и это только цветочки! А еще варианты, когда вся книга на русском языке, а информация об авторе на иностранном. И весь этот мусор вольготно чувствует себя в базе... Вот пока все!
почему из "Базы" и "Отсева" снова возвращаемся в "Проход по списку файлов"?
потому-как цикл...
ЦитатаPFN ()
Эти файлы или должны редактироваться или удаляться без следа! Особенно совпавшие по МД5.
что и куда - решать только пользователю, посему тамочки есть запрос. Захочет пользователь - кинет в базу, захочет - в отсев, захочет - в мусор.
ЦитатаPFN ()
Фильтр Пользовательского отбора стоит непосредственно перед добавлением в базу.
естественно, если уйдет по другим признакам, зачем дальше анализировать?
ЦитатаPFN ()
Поэтому этот фильтр, на мой взгляд, нужно ставить ДО проверки по МД5, чтобы ускорить процесс.
а как мсьё планирует разбираться с многофайловыми архивами? Нет, эта система отработана и опробована. Разделять фильтр на до и после не целесообразно
ЦитатаPFN ()
Что касается отсеивания дубликатов по названию книги, то эту процедуру лучше делать уже непосредственно в базе, задействуя разные варианты поиска/отбора.
угу... дефрагментировать базу - наше всё... Зачем добавлять книгу в базу что б ее оттуда потом удалять? Или я чего-то не понял?
ЦитатаPFN ()
И весь этот мусор вольготно чувствует себя в базе...
и будет чувствовать, на то и ручки есть... Кстати, вот походу и вопросик по картиночке: по той же самой Кристи, есть две книги. Мы, люди, видим что это одно и то же. Как это поймет программа, если тайтлы разные? Хрен с ним, поняла.... Какую оставлять будем? Дальше пойдем, книги одинаковые, форматы - разные... Че делаем? Дальше? Я только на одних описаиях возможных дублей книгу напишу.
Просьба: пока мне надо "что", "как" - я сам сделаю. Будет фильтр до или после, будет быстрее или медленнее - сейчас не важно. Важно понять что делать. Только тип и язык - да нет проблем. Только сразу предупреждаю - в языках полный расколбас. ru,rus, russian и прочее со всеми вариациями языков, больших-маленьких букв, перепутанных раскладок (например КГ) и другие ... Категорично отбрасывать - потерять половину книг. drSerj
Если ему в библиотеке нужны файлы/книги близнецы - то я не против!
Цитатаdrserj ()
естественно, если уйдет по другим признакам, зачем дальше анализировать?
Конечно, сначала высчитаем МД5, пройдем все рогатки, а потом окажется, что это книга на языке племени Мумба-Юмба...
Цитатаdrserj ()
а как мсьё планирует разбираться с многофайловыми архивами?
Я почему-то представлял себе, что архивы распаковываются и обрабатываются отдельные файлы... Тут я пас.
Цитатаdrserj ()
угу... дефрагментировать базу - наше всё... Зачем добавлять книгу в базу что б ее оттуда потом удалять? Или я чего-то не понял?
Я немного неправильно выразился. Я показал скрин фрагмента таблицы не базы, а таблицы предварительного отбора проанализированных после сканирования файлов. В таблицу не попали файлы НЕ ФБ2, файлы не валидные (с ошибками) и файлы на других языках. Все они были перемещены в соответствующие папки для принятия окончательного решения по ним. После этого ручками, используя сортировку по разным полям, из таблицы и с диска были удалены книги определенных жанров (Любовные романы, Драматургия и т.д. по вкусу) А теперь...
Цитатаdrserj ()
Какую оставлять будем? Дальше пойдем, книги одинаковые, форматы - разные... Че делаем?
Ручками, ручками смотрим и выбираем лучшую... Картинку для сравнения я сбрасывал раньше...
Цитатаdrserj ()
Важно понять что делать. Только тип и язык - да нет проблем.
Да критериев сколько угодно... Жанры (Биографии, Биология и т.п.). Язык..
Цитатаdrserj ()
Только сразу предупреждаю - в языках полный расколбас. ru,rus, russian и прочее со всеми вариациями языков, больших-маленьких букв, перепутанных раскладок (например КГ) и другие ... Категорично отбрасывать - потерять половину книг.
С языками 2 пути: 1. ориентироваться на тэг "<lang>ru<lang>" Здесь, конечно, полный бардак с написанием и все предусмотреть очень сложно 2. Программно анализировать фрагмент основного текста порядка 5000 символов и подсчитывать символы кириллицы и латиницы (что я у себя и делаю). Если символов латиницы больше - отсеиваем файл/книгу...
Добавлено (14.05.2017, 19:38) --------------------------------------------- Вот ссылка на файл с кодом: https://yadi.sk/i/n4MIe4kx3J95Aj
=============================== Приказ, который может быть понят неправильно, обязательно будет понят неправильно
Если ему в библиотеке нужны файлы/книги близнецы - то я не против!
Я, например, держу всё, ибо нарывался неоднократно на ситуацию, когда новые файлы хуже старых. Обработать ручками пол-лимона файлов мне не под силу, место есть, храню всё.
ЦитатаPFN ()
Конечно, сначала высчитаем МД5, пройдем все рогатки, а потом окажется, что это книга на языке племени Мумба-Юмба...
А тут единого алгоритма нет и не может быть. Где-то одно сработает, где-то другое... Главное что бы сработало...
ЦитатаPFN ()
1. ориентироваться на тэг "<lang>ru<lang>"
я за этот анализ и говорю...
ЦитатаPFN ()
2. Программно анализировать фрагмент основного текста
мдя? Пользователь будет жить вечно? Да и этот метод не дает однозначного результата... Да и не может дать... Так, на уровне "а вдруг угадаю"
ЦитатаPFN ()
подсчитывать символы кириллицы и латиницы (что я у себя и делаю).
Для небольшого количества книг - может и выход. Но в таком случае - глазками быстрее и надежнее. А как в случае сотен тысяч книг, да еще во многих случаях не fb2? А если в архиве одна книга файлами побитая? Книжка русская, а аннотация - английская... drSerj
Да и этот метод не дает однозначного результата... Да и не может дать... Так, на уровне "а вдруг угадаю"
Метод очень даже хорошо срабатывает. Приблизительно на 5000 файлов всего 3-4 ошибки.
Цитатаdrserj ()
Для небольшого количества книг - может и выход. Но в таком случае - глазками быстрее и надежнее. А как в случае сотен тысяч книг, да еще во многих случаях не fb2?
"Небольшое количество" - это сколько? Сколько файлов содержит ежедневное или еженедельное пополнение библиотеки? Думаю, что около 20 тыс. Это количество "ручками и глазками" быстрее не обработаешь... С файлами не ФБ2, особенно pdf, djvu нужно искать другое решение. Вот их только "ручками и глазками"...
Цитатаdrserj ()
А если в архиве одна книга файлами побитая? Книжка русская, а аннотация - английская...
Ну... в нашей жизни все бывает... Но это явление не массовое... Кроме того, я же предлагаю анализировать текст, заключенный в тэгах "<body></body>", а не в тэгах метаданных книги. =============================== Приказ, который может быть понят неправильно, обязательно будет понят неправильно
Метод очень даже хорошо срабатывает. Приблизительно на 5000 файлов всего 3-4 ошибки.
не верю. при наличии только англ\рус - возможно. При наличии десятков языков (как у меня) - не верю!
ЦитатаPFN ()
Сколько файлов содержит ежедневное
обычно до 200 (80-150), но.... а кто вообще говорит про онлайн??? обычный человек, обычная библиотека, сотни любимых книг... зачем автомат? Мы опять путаем грешное с праведным.
1.Начальная каталогизация. Если из онлайн библиотеки - из их базы и берем. Если накачано ручками - ручками и обрабатываем. 2.Пополнение. Если сетевая - нехрен руками импортировать, гребем из их базы. Если не сетевая - больше пары книг в день - сомневаюсь.
ЦитатаPFN ()
Кроме того, я же предлагаю анализировать текст, заключенный в тэгах "<body></body>", а не в тэгах метаданных книги.
это только fb2, в 99 случаях из 100 - инфа есть в онлайн-библиотеках, ибо для них и лепится.
Короче, предлагаю изначально не перенаворачивать программу "ИИ", а тупо сделать ядро с элементарными функциями. А если начнем с написания Искусственного Интеллекта - на нем и загнемся : drSerj
 Главная
Главная